前言
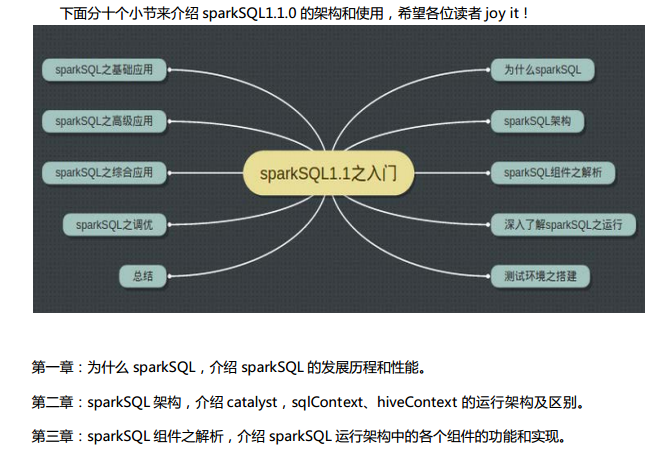
第1章 为什么Spark SQL?
第2章 Spark SQL运行架构
第3章 Spark SQL组件之解析
第4章 深入了解Spark SQL运行计划
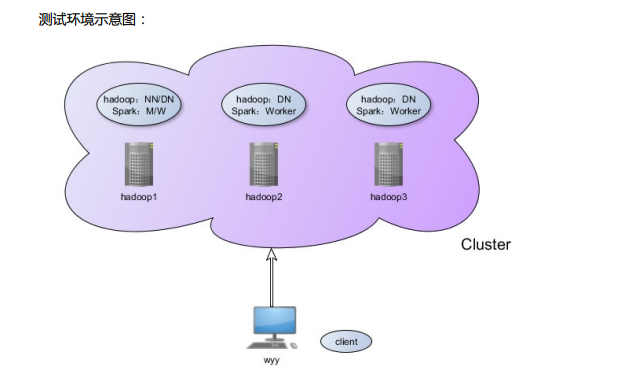
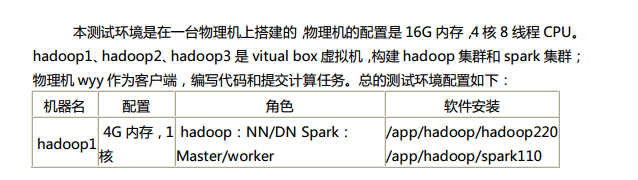
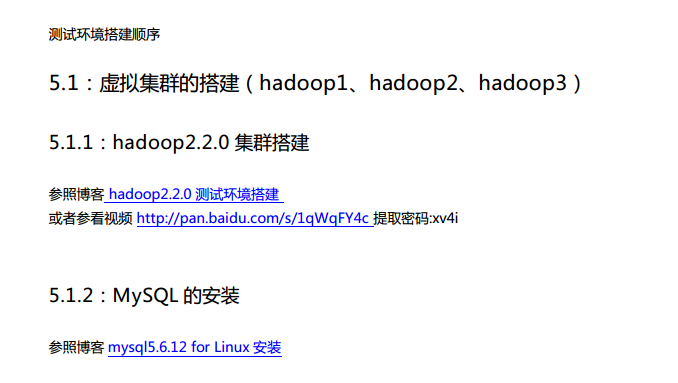
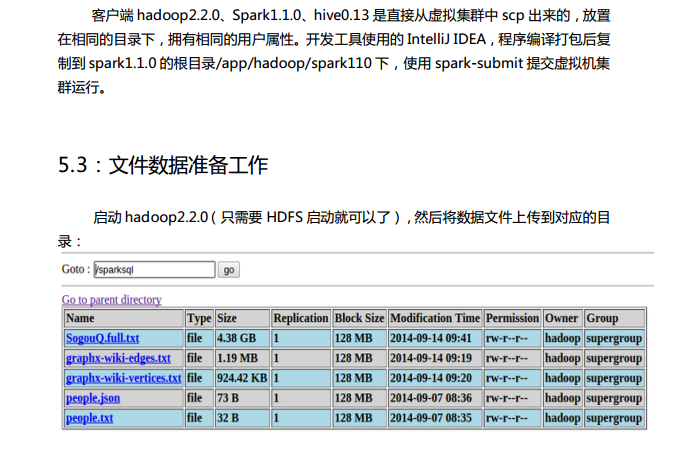
第5章 测试环境之搭建
第6章 Spark SQL之基础应用
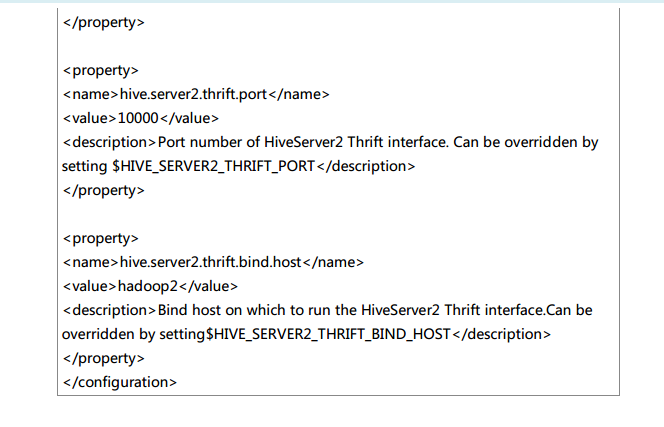
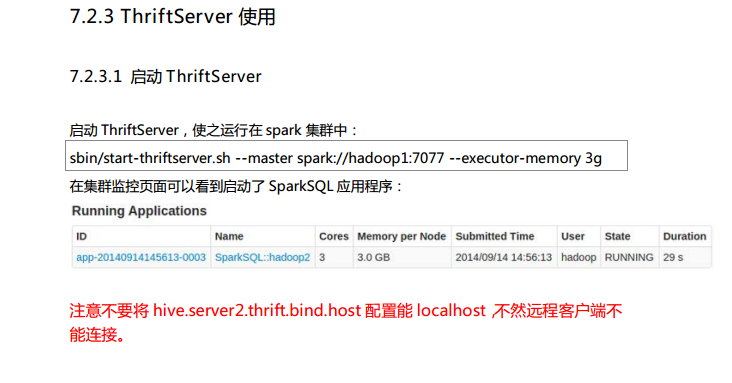
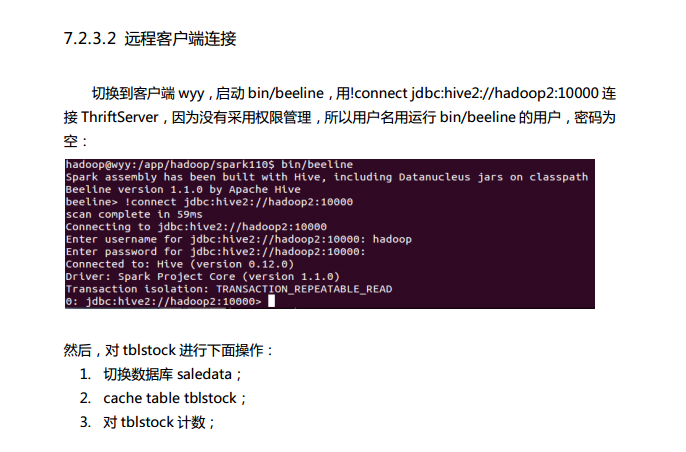
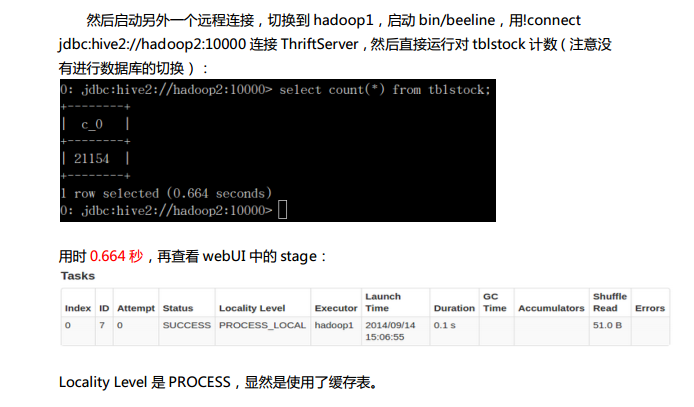
第7章 ThriftServer和CLI
第8章 Spark SQL之综合应用
第9章 Spark SQL之调优
第10章 总结



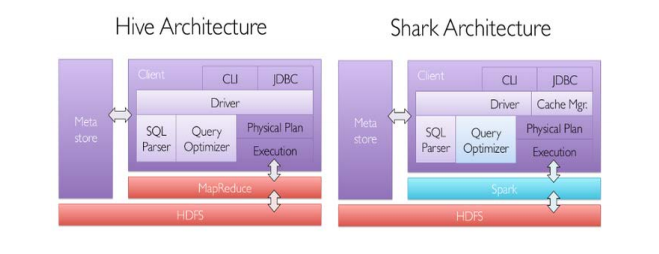

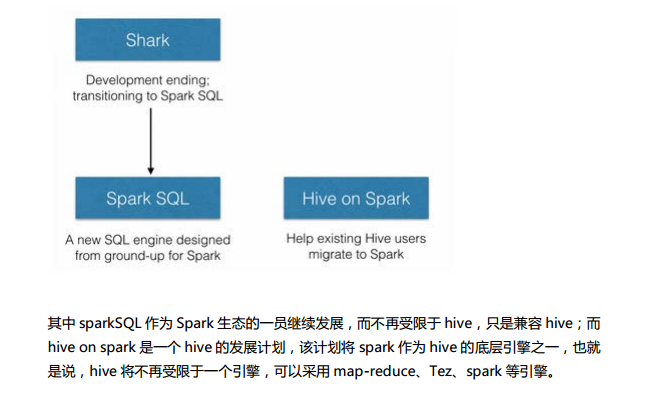
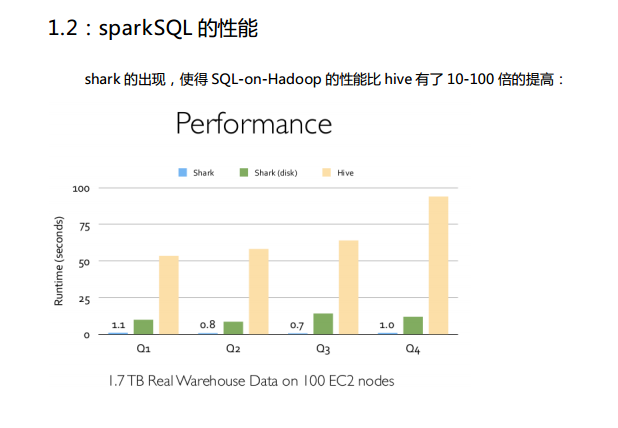
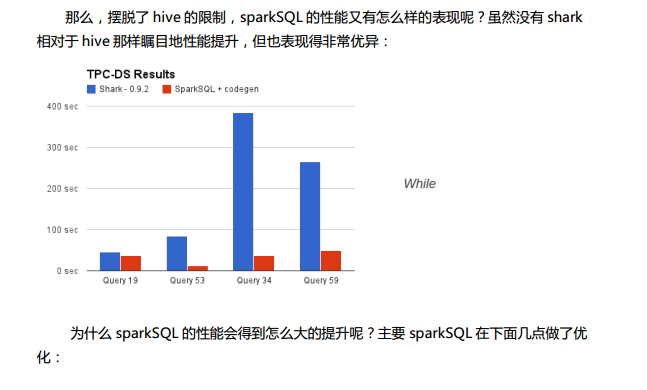



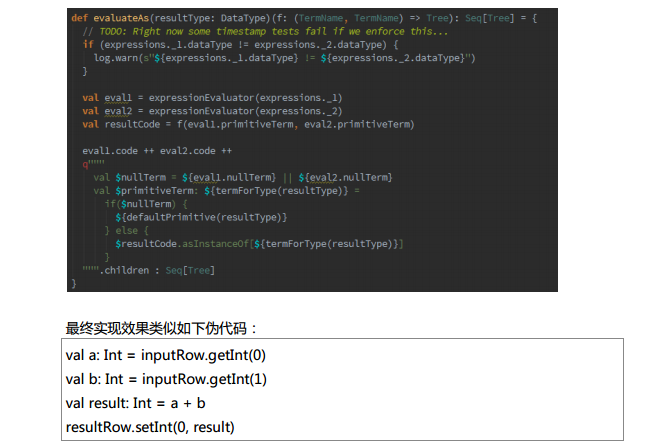
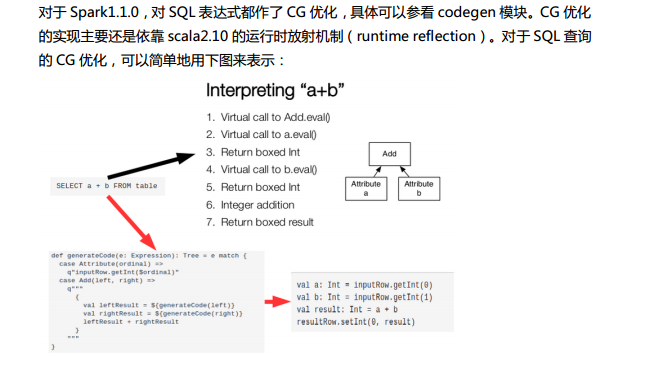

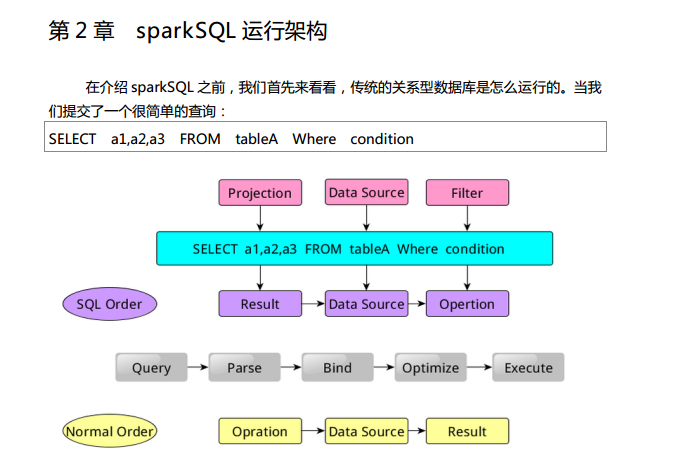

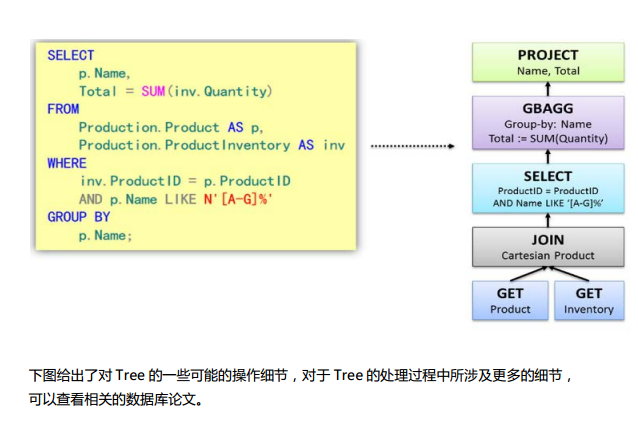
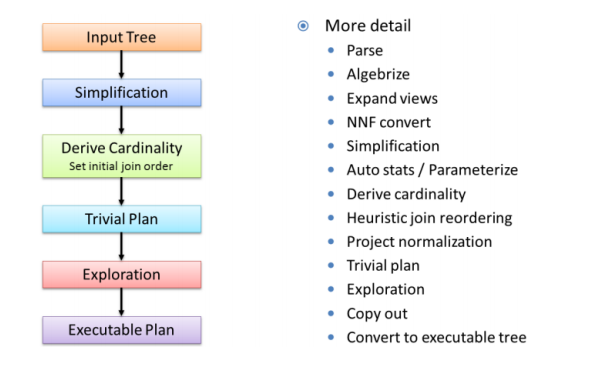
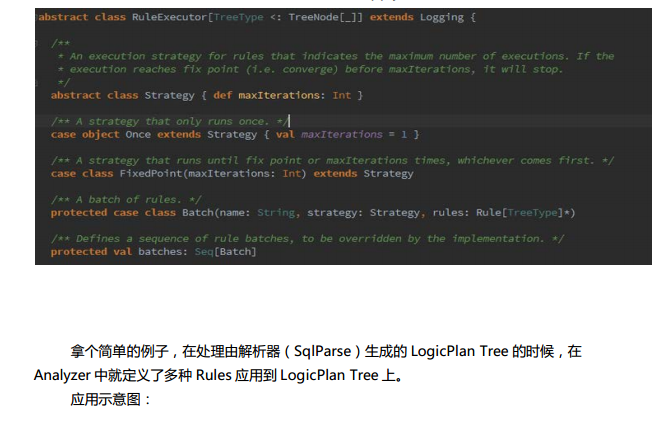
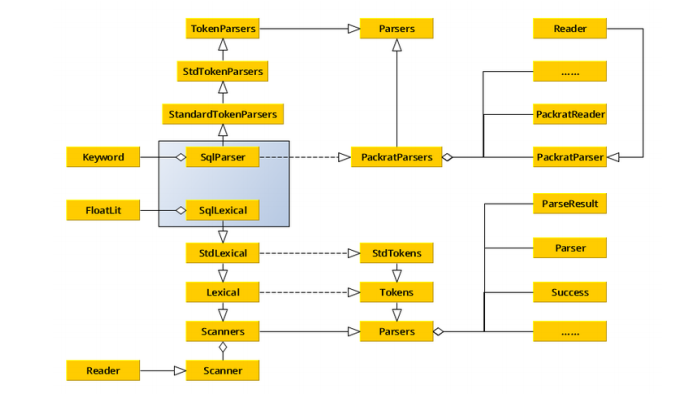
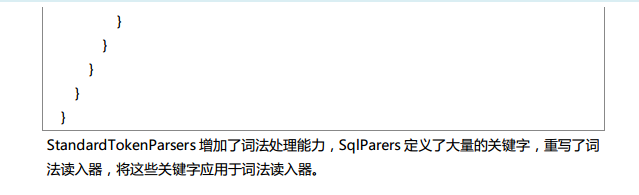
Spark SQL中的两个重要概念Tree和Rule、然后介绍一下Spark SQL的两个分支sqlContext和hiveContext

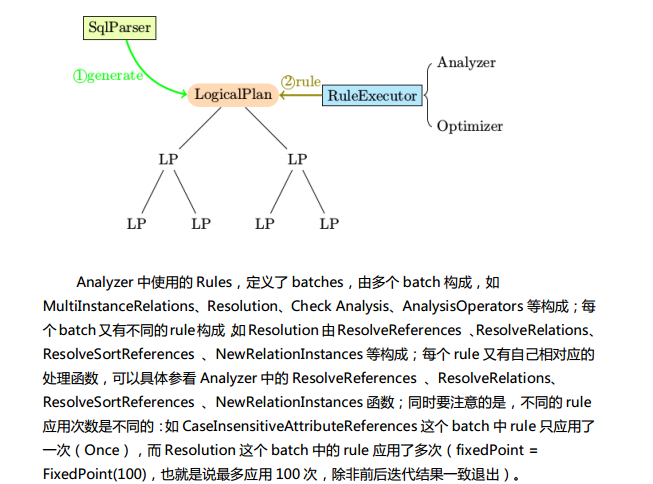
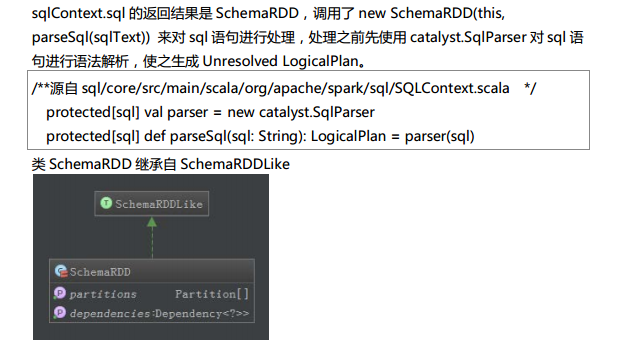
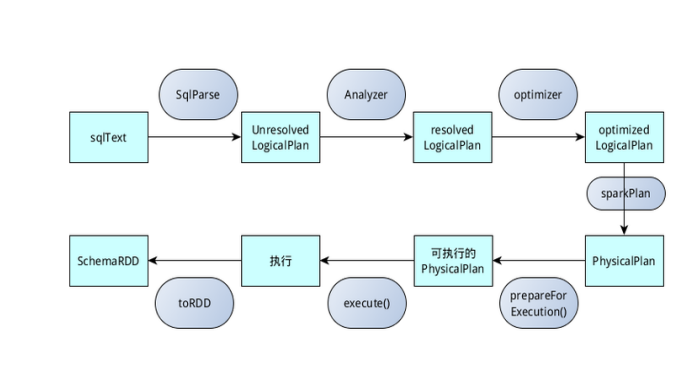
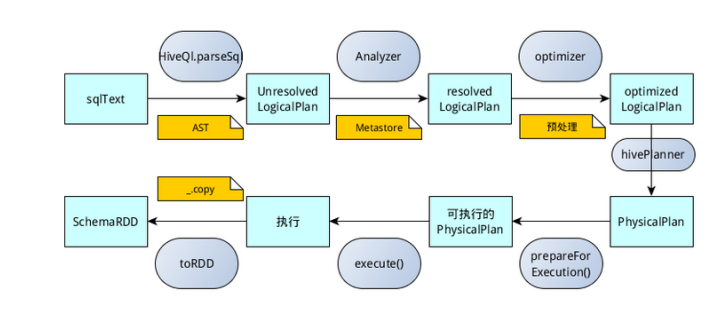
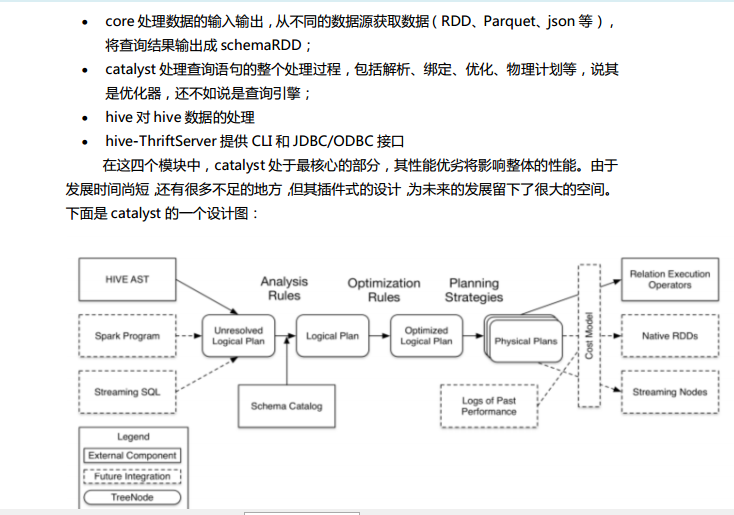
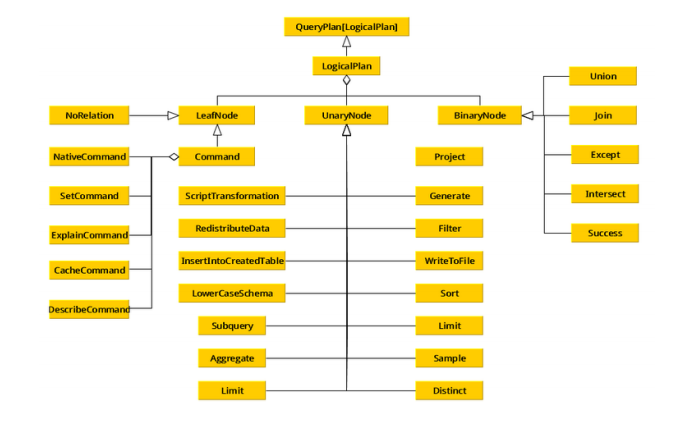
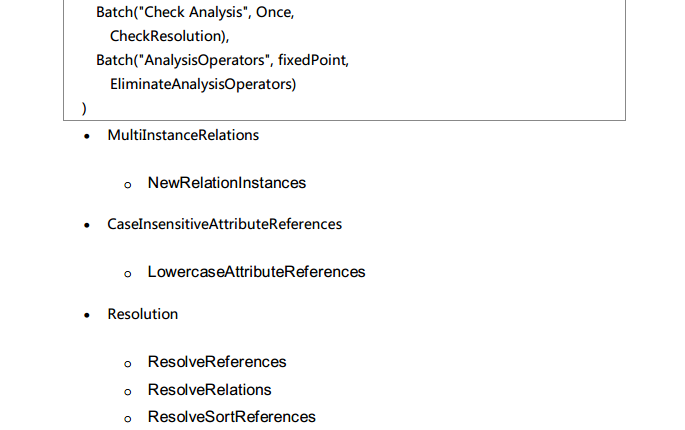
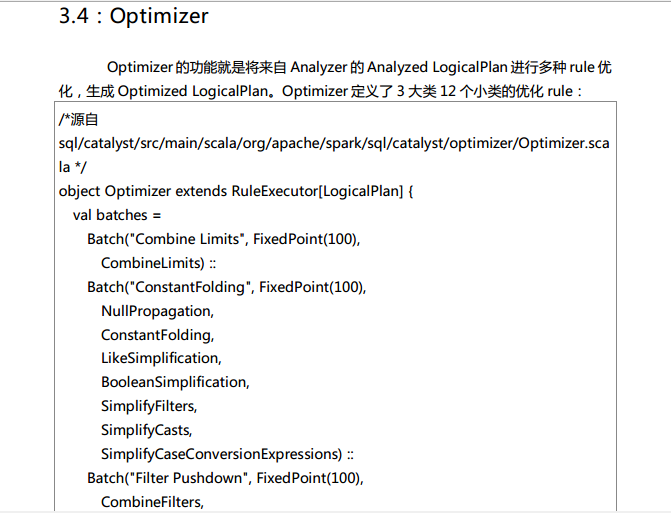
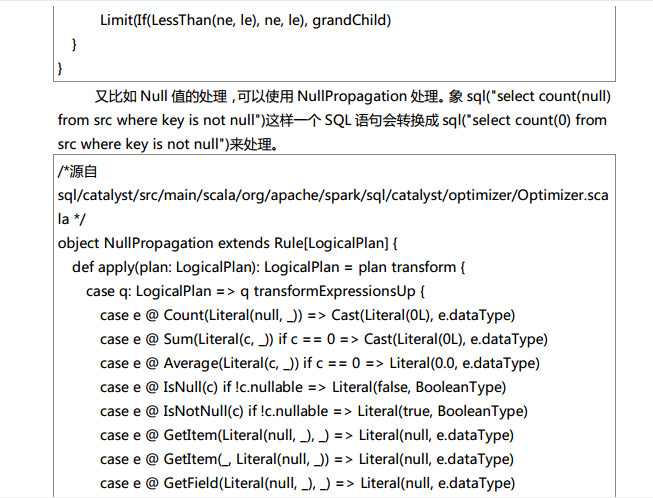
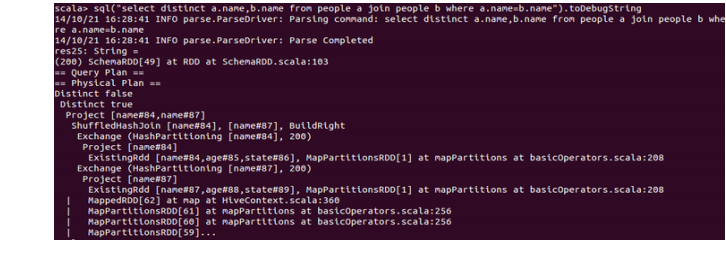
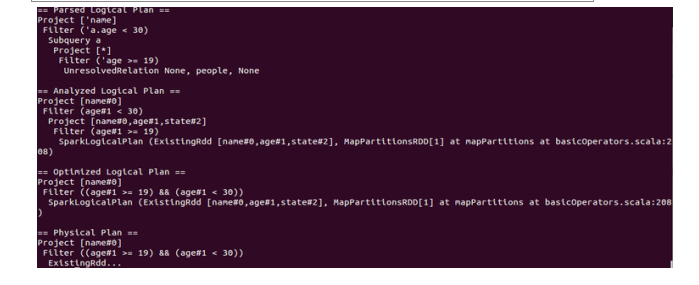
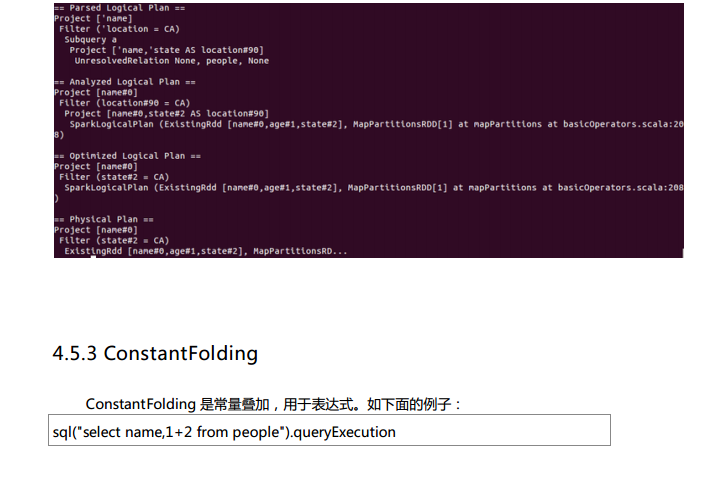
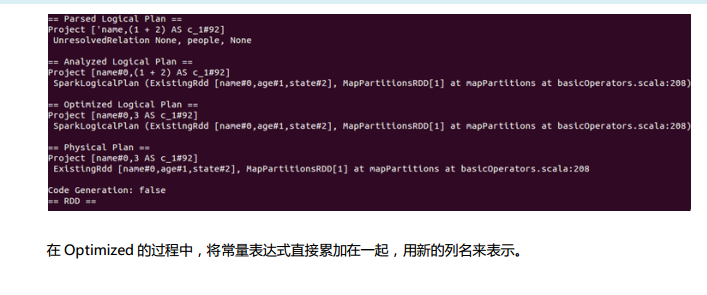
Spark SQL对SQL语句的处理和关系型数据库对SQL语句的处理采用了类似的方法,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。


























































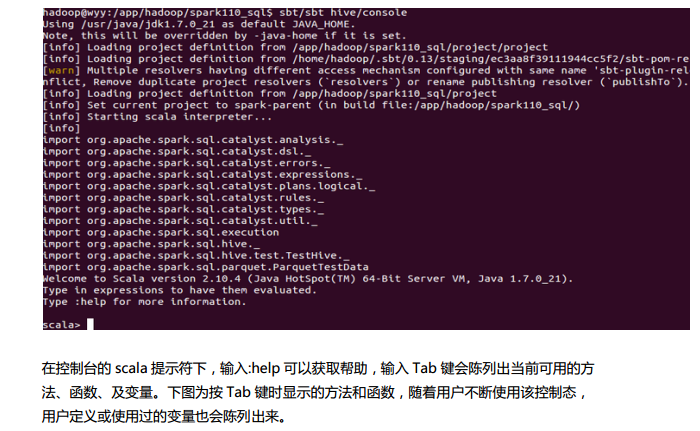




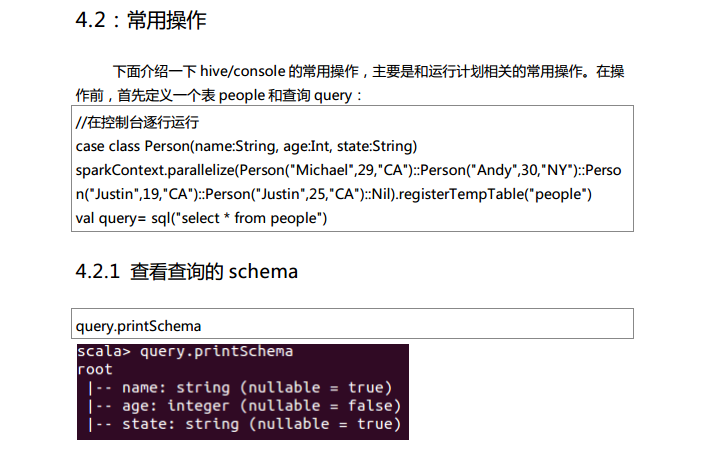
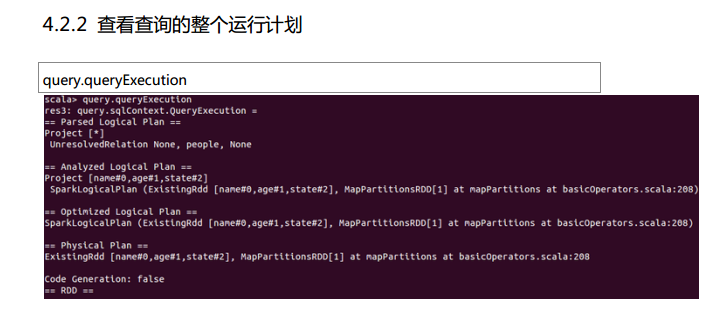
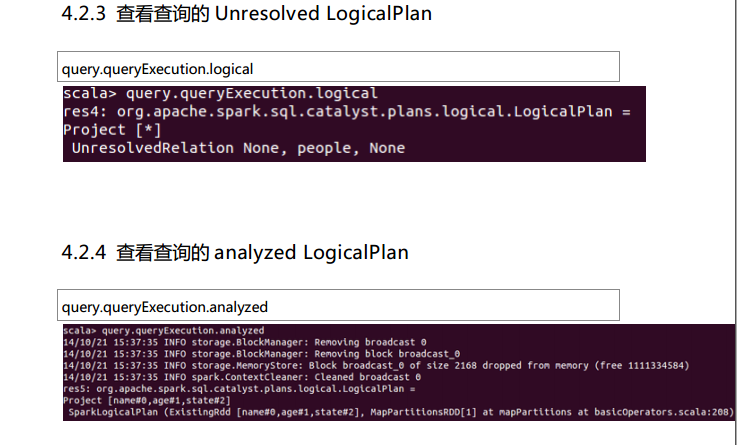

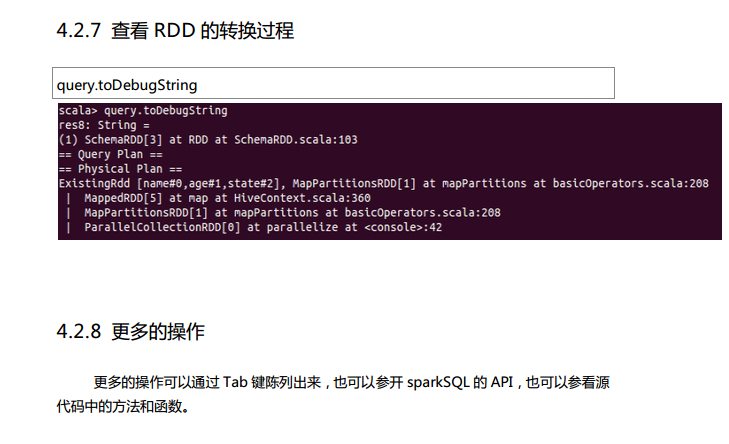


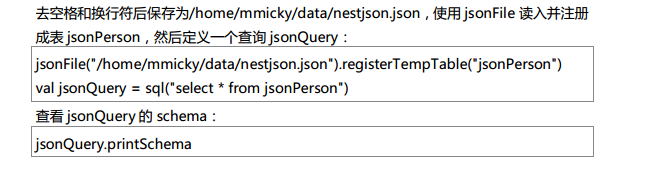
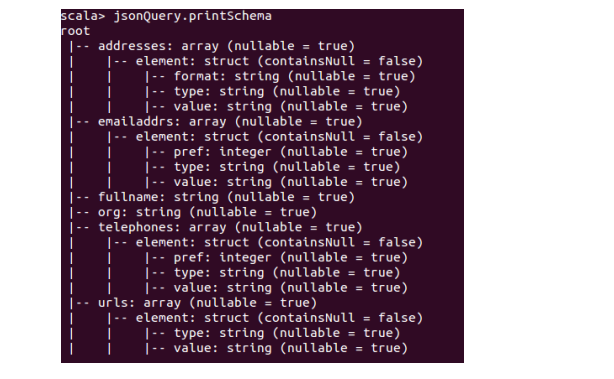
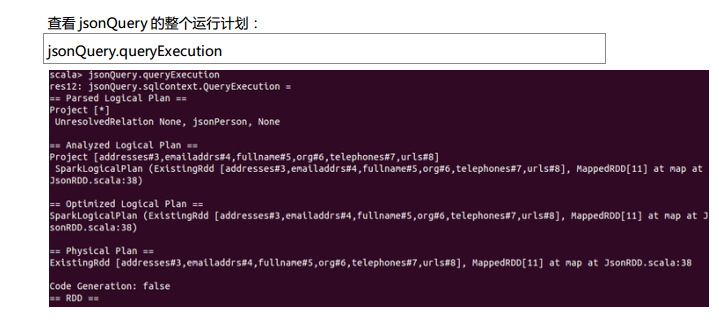

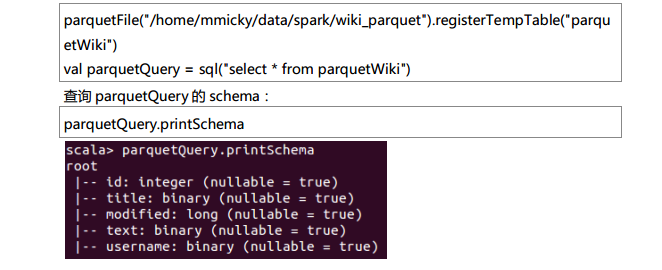
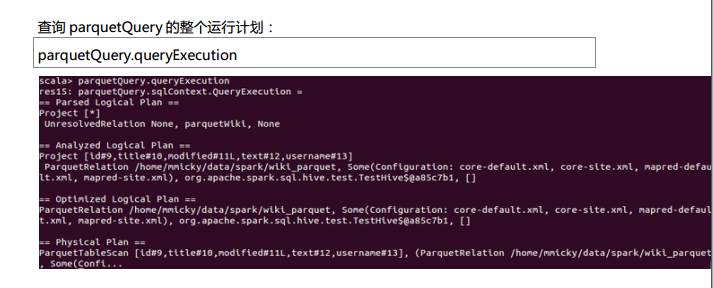

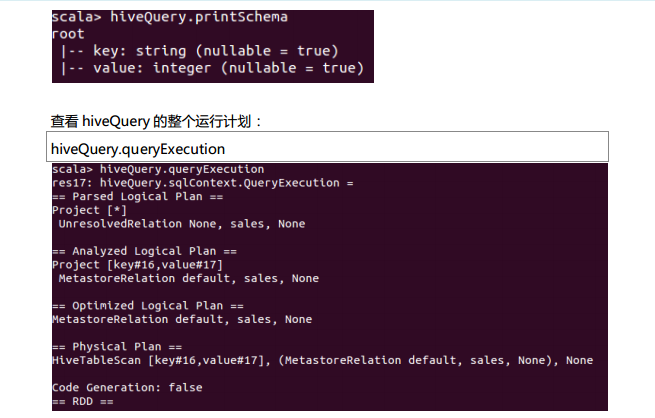

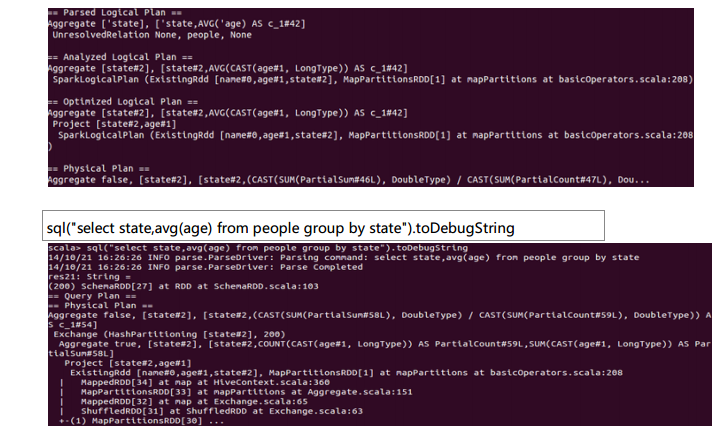
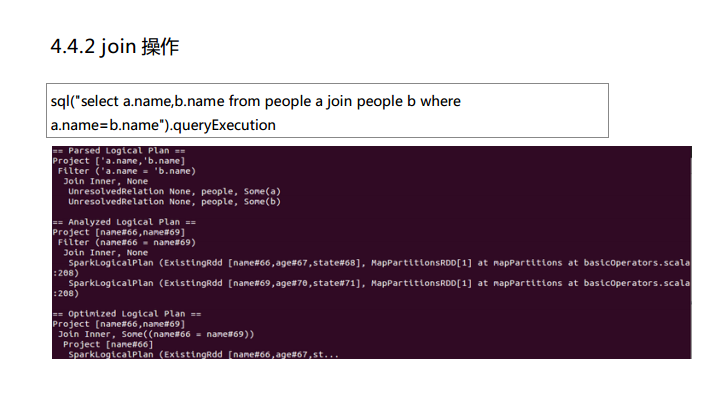
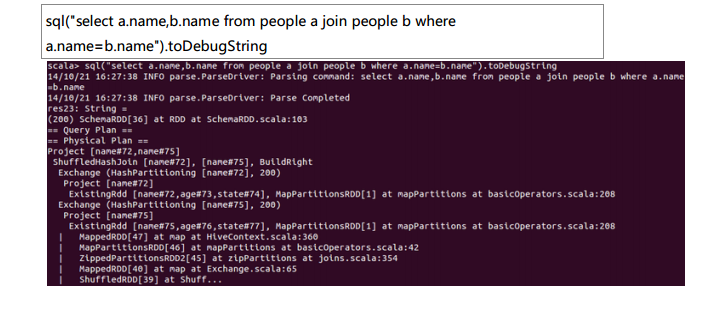
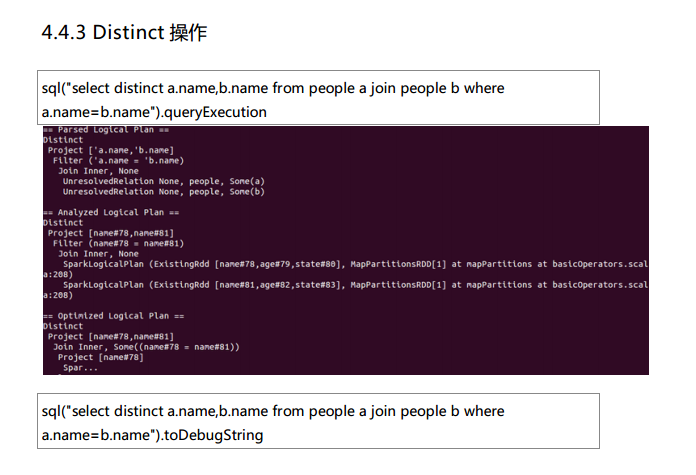




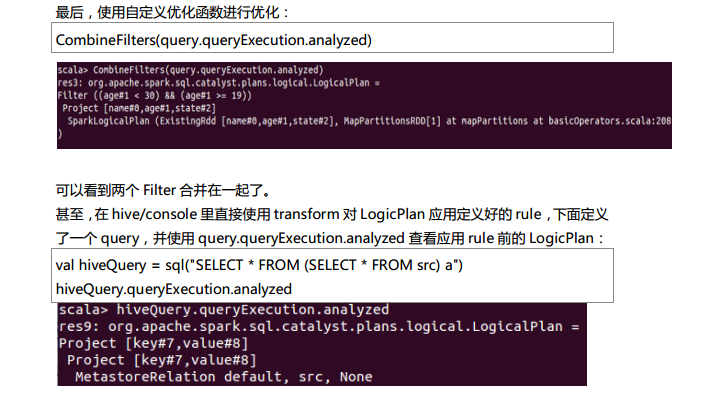
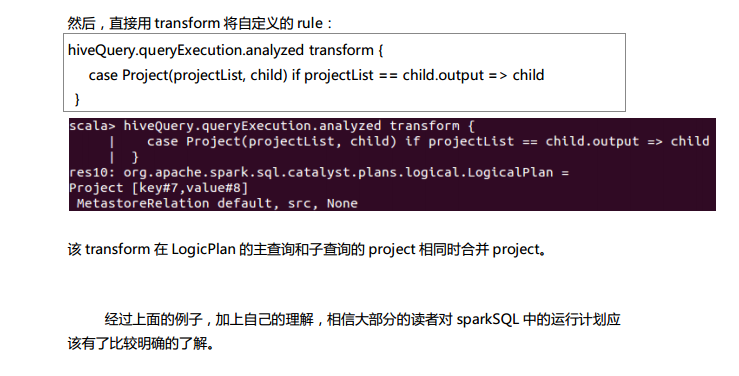

测试数据下载地点:http://pan.baidu.com/s/1eQCbT30#path=%252Fblog中的sparkSQL_data.zip (目前,已经被取消)